
เรียนสถิติด้วยภาพ ตอนที่ 14 สูตรทดสอบไคสแควร์
เมื่อไหร่ที่ใช้ไคสแควร์ ?
ตอบแบบกำปั้นทุบดินคือ เมื่อผลการทดลองสามารถคำนวณค่าไคสแควร์ของการทดลองออกมาได้
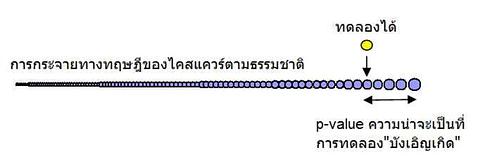
จากภาพ หากเรารู้ว่า มีค่าไคสแควร์ที่บรรยายการทดลองของเราเป็นเท่าไหร่ (ก้อนสีเหลือง) และการทดลองของเรา บรรยายด้วยค่า degree of freedom เป็นเท่าไหร่ นั่นคือ เราก็มาเทียบกับการแจกแจงทางทฤษฎี(ที่เคยพูดไว้ก่อนหน้าในตอนก่อน ๆ) ว่า ผลการทดลองของเรา เบี่ยงเบนไปจากทฤษฎีมากแค่ไหน
ถ้ายังจำได้ ไคสแควร์บอกถึงว่า หากปล่อยให้ขี้เมาเ้ดินแบบสุ่มไปสักพัก จำนวน v ก้าว เมื่อ v มีค่ามากพอสมควร (หรือ degree of freedom = v) พื้นที่ซึ่งเขาเดินผ่าน จะมีค่าเท่าไหร่
ถ้าเขาเดินคลุมพื้นที่ได้เยอะมหาศาล นั่นไม่น่าเป็นไปได้ เพราะแสดงว่า เขาวิ่ง หรือซิ่ง
ถ้าเขาเดินคลุมพื้นที่ได้ใกล้ศูนย์ นั่นก็ไม่น่าเป็นไปได้ เพราะแสดงว่า เขาเกเร ไม่ยอมเดิน เล่นนั่งอยู่กับที่
ค่าที่เป็นธรรมชาติคือ ควรได้ค่าในช่วงหนึ่ง ไม่น้อยเกิน ไม่มากเกิน
ถ้าผลการทดลองของเรา สามารถคำนวณหาไคสแควร์ที่ degree of freedom = v ได้ (ก้อนสีเหลือง) เราก็นำมาเทียบกับการแจกแจงของขี้เมานับแสนนับล้านคนที่เดิน v ก้าวเหมือนกัน แล้วเอาพื้นที่คลุมพิสัยการเดินมาพล็อตเทียบ (ก้อนสีม่วง) ซึ่งก้อนสีม่วงคือ การกระจายตัวตามธรรมชาติที่ degree of freedom = v นั้น
ก้อนเหลือง ยิ่งเคลื่อนไปทางขวามาก (ขนาดโตขึ้น) โอกาสเกิดได้เองตามธรรมชาติ (p-value) ก็ยิ่งน้อยลง (สีม่วงเกิดตามธรรมชาติ)
เนื่องจากค่าไคสแควร์ของผลการทดลอง จะบอกว่าผลการทดลองผิดคาดหมาย ดังนั้น อาจกล่าวได้ว่า ยิ่งผลการทดลองผิดคาดหมายมากเท่าไหร่ p-value ก็จะยิ่งน้อยลงเรื่อย ๆ
สูตรของไคสแควร์ที่ใช้อธิบายการทดลอง ถ้าไปดูในตำรา จะมีหน้าตาว่า
ที่มาสูตร http://en.wikipedia.org/wiki/Pearson%27s_chi-squared_test
ดูสูตรแล้ว เอ๊ะ ไสยศาสตร์ชัด ๆ
แต่จริง ๆ แล้ว ที่มาของมัน ไม่ได้ซับซ้อนเกินไปนัก
มันก็คือ ผลรวมของค่า Z ยกกำลังสองนั่นเอง เมื่อ Z คือการเบี่ยงเบนจากค่าเฉลี่ยกี่ SD
ซึ่งก็คือนิยามไคสแควร์ทางทฤษฎี
แต่ทำไมหน้าตามันเป็นอย่างนี้ ?
ตรงนี้ต้องพาดพิงไปถึงแนวคิดเรื่องการแจกแจงทวินาม ซึ่งยังไม่เคยพูดถึงมาก่อน ซึ่งจะกล่าวถึงอย่างสั้น ๆ แบบไม่กล่าวถึงความเป็นมา
หากเรารู้ว่า กระบวนการหนึ่ง มีโอกาสเกิดเหตุการณ์อะไรสักอย่าง เท่ากับ p และทำซ้ำ N ครั้่ง
กระบวนการนี้ เราคาดหมายว่า จะเกิดเหตุการณ์ดังกล่าว เท่ากับ Np
และค่า variance ของการเกิดเหตุการณ์ดังกล่าว จะเท่ากับ Np(1-p) ซึ่งค่า standard deviation จะเป็น รากที่สองของ Np(1-p)
หากกระบวนการดังกล่าว มีค่า p น้อยมาก ๆ จะทำให้ Np(1-p) กับ Np แทบจะไม่ต่างกัน การแจกแจงทวินามกรณีดังกล่าวจะเรียกการแจกแจงปัวซง ซึ่งถ้ามีค่าเฉลี่ย Np ก็จะมีค่า standard deviation ประมาณ รากที่สองของ Np
Np คืออะไร ? ถ้าผมซื้อหวย 1000 ใบ มีโอกาสถูกเลขท้ายสองตัวคือ 1 ใน 100 ผมควรจะถูกหวย 10 ใบ
ของจริงอาจถูกมากกว่านั้น หรือน้อยกว่านั้น แต่ Np ตอนนี้ ก็จะหมายถึง ความถี่การเกิดเหตุการณ์ที่คาดหวัง (expected frequency; E)
ถ้าใช้ E แทน Np (ความถี่ที่คาดหมาย)กระบวนการดังกล่าว จะมีค่าเฉลี่ย E และค่า standard deviation ประมาณ รากที่สองของ E
ดังนั้น หากเราพบความถี่จากการทดลองคือ O
ค่า Z ของกรณีนี้ ก็จะเป็น (observe - mean) หาร standard error = (O-E)/รากที่สองของ E
หากยกกำลังสอง ก็จะได้ว่า Z กำลังสอง มีค่าเท่ากับ (O-E) ยกกำลัง 2 แล้วหารด้วย E
ดังนั้น ไคสแควร์ ซึ่งเป็นผลรวมของ Z ยกกำลังสอง จึงมีหน้าตาอย่างที่เราเห็น
ถ้าเรามองเข้าไปในเซลล์ แต่ละเซลลมีค่าคาดหวังคือ E ค่า standard deviation ของ E ก็คือรากที่สองของ E
แต่ตัวเลขในเซลล์นั้น เราเจอ O ดังนั้น การเบี่ยงไปจากค่าคาดหวัง Z ก็คือ (O-E) หาร sd คือหารรากที่สองของ E
เมื่อหาไคสแคร์ ก็คือจับ z มายกกำลังสอง ก็ได้ (O-E)^2 หาร E แล้วรวมทุกเซลล์เข้าด้วยกัน
ส่วนเรื่องว่า ในทางปฎิบัติ ค่า expected frequency จะได้มายังไง หรือจะดูได้ยังไงว่า degree of freedom เท่าไหร่ จะขยายความในตอนต่อไป
สนใจอ่าน เรียนสถิติด้วยภาพ แบบครบทุกตอน เข้าไปที่
http://www.gotoknow.org/posts?tag=เรียนสถิติด้วยภาพ
ความเห็น (0)
ไม่มีความเห็น