
เรียนสถิติด้วยภาพ ตอนที่ 3 Confidence Interval, alpha & beta
เวลาเรามีข้อมูลของประชากรสองกรณี แต่ละกรณีหากไปเก็บข้อมูลมาหลาย ๆ ครั้งโดยให้หลายทีมออกไปเก็บ แล้วหาเป็นค่าเฉลี่ยลงจุด ค่าเฉลี่ยที่ได้จากแต่ละทีมก็จะไม่เหมือนกันนัก ผลคือ แต่ละกรณีก็จะมีหลายจุด แต่โดยรวม เราก็จะเห็นกองเป็นหย่อม สองกรณีก็มีสองหย่อม
หากเราหาช่วงความเชื่อมั่นของค่าเฉลี่ยแต่ละหย่อมพร้อม ๆ กัน ให้มีขนาดที่ทำให้ขอบของทั้งสองวงนี้แตะกันพอดี ค่า alpha level (ขอบนอกที่ตัดทิ้ง) ก็จะเรียกว่า p-value
p-value จะมีความหมายทางเรขาคณิตว่า ทั้งสองหย่อมของค่าเฉลี่ย จะเกยกันเองได้มากไหม
ถ้า p-value มาก แสดงว่า ทั้งสองหย่อม เกยกันมาก แสดงว่า มีการพัวพันกันยุ่งเหยิงจนแยกขาดจากกันไม่ได้ ทางสถิติก็จะถือว่า ไม่ต่างกัน
ถ้า p-value น้อย ก็จะแสดงว่า การเกยกันน้อย ไม่มีการพัวพันกันเอง ทางสถิติก็ถือว่า แยกขาดจากกันได้ เรียกว่าเกิดความแตกต่างกันทางสถิติ
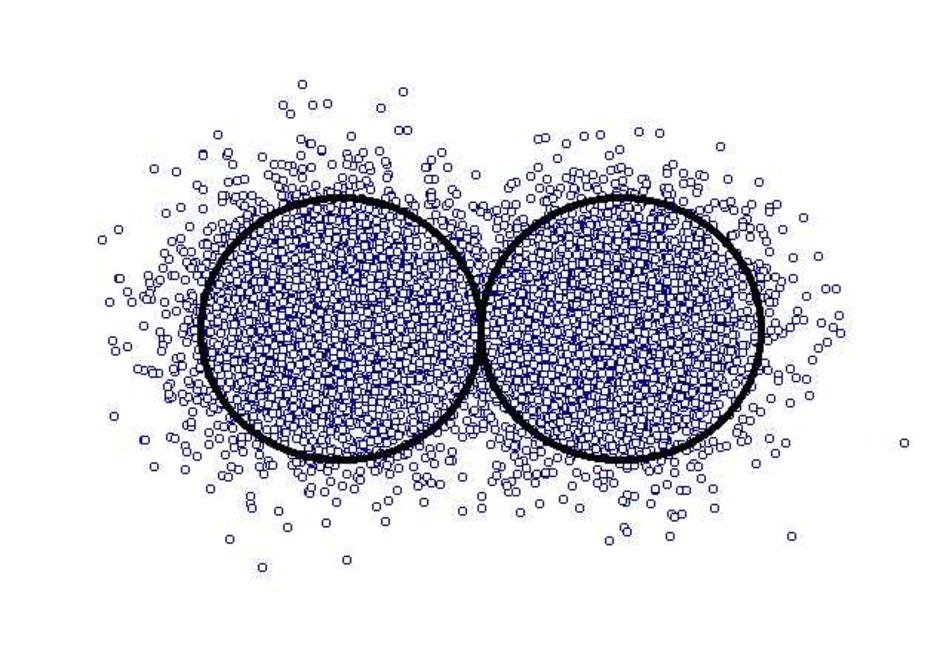
สมมติต่อไปอีกว่า รูปข้างบน เป็นรูปถ่ายของดาว ที่เราคาดว่า เป็นดาวคู่ แต่จริง ๆ แล้วก็ยังไม่เคยมีหลักฐานว่ามันคู่จริงมั้ย อาจเป็นดาวเดี่ยว แต่เราจะพิสูจน์ว่าคู่หรือเปล่า โดยดูจากระดับการเกยกันเอง (p-value)
สมมติต่อไปอีกว่า เราฟันธงบอกว่า ระดับการเกยกัน อยู่ที่ p-value = 0.07 โดยหอดูดาวแห่งที่หนึ่ง ถ่ายรูปมาได้ตามรูปแรก โดยใช้กล้องดูดาวคุณภาพสูง ก็จะเห็นรูปถ่ายที่มี pixel แน่นไปหมด
pixel ก็เหมือนจุดหนึ่งจุด ที่เรามองหน้าจอเห็นเป็นภาพ จริง ๆ แล้วเรากำลังมอง pixel เป็นจำนวนมหาศาลที่มีหลากสี ที่เรียงต่อกันขึ้นมาเป็นภาพ เป็นตัวอักษรให้เรามองเห็น
(pixel ที่เล็กที่สุดที่เป็นไปได้ในการแสดงผล ก็จะเป็น 1x1 pixel มีไว้สำหรับการทำ black hat optimization ดังปรากฎใน วรรณกรรมของจีนแต่โบราณ)
สมมติว่า ณ เวลา และสถานที่เดียวกันกับหอดูดาวนั้น
เราใช้กล้องดิจิทัลส่วนตัวถ่ายรูปไปด้วย ภาพเดียวกัน
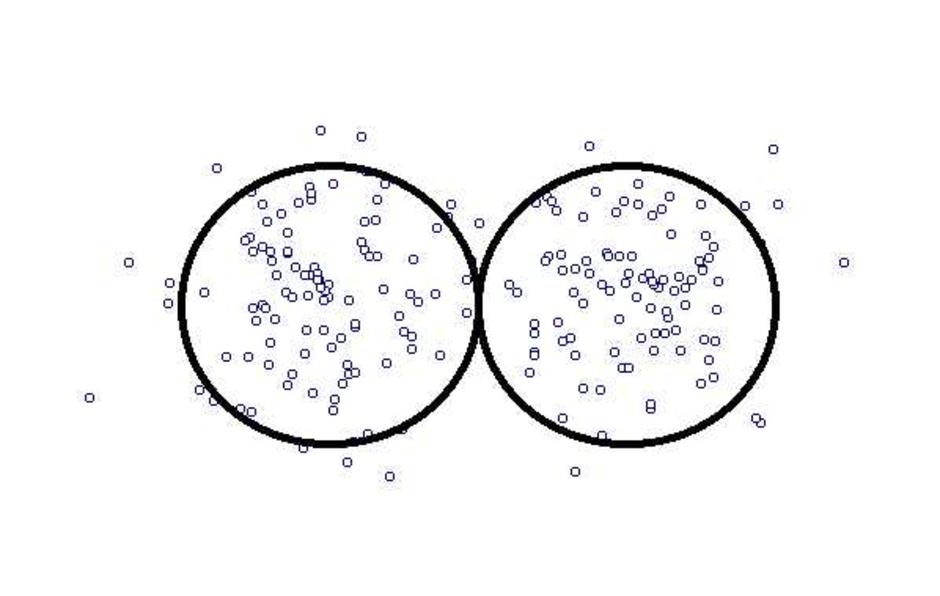
และถ่ายโดยใช้มือถือถ่าย โดยทำที่เวลาและสถานที่เดียวกัน ทั้งสามกรณี
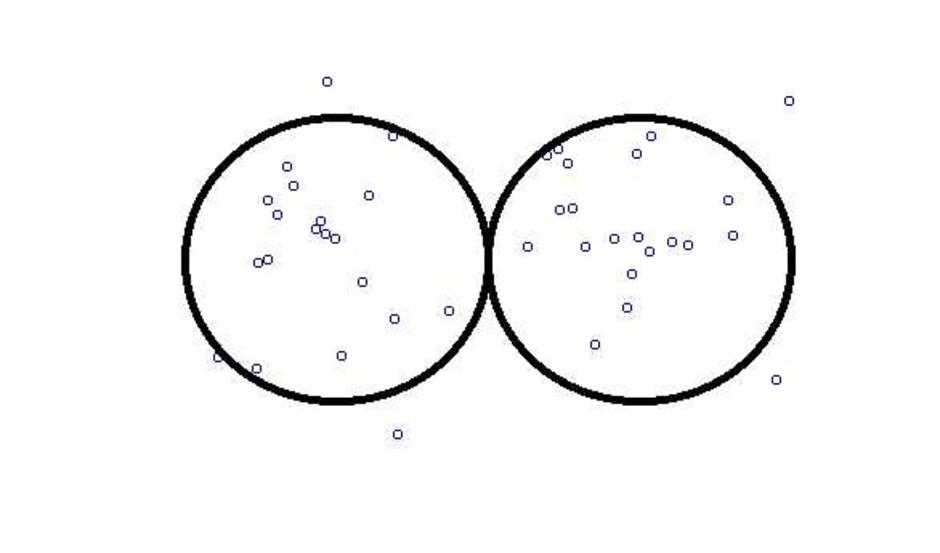
การที่เราเห็นต่างกัน เพราะใช้กล้องที่คุณภาพต่างกัน บันทึก pixel ได้มากน้อยผิดกัน
ทุกกรณี ปรากฎว่า มี p-value เหมือนกันหมด
แต่กรณีไหนที่น่าเชื่อถือกว่า ?
รูปบนสุด จะมีข้อมูลที่หนาแน่นกว่า เรียกว่า มี power สูงสุด (ก็จะมี beta error ต่ำสุด) จะน่าเชื่อถือที่สุด
รูปที่อยู่ถัด ๆ ลงมา ก็จะมี power ต่ำลง และมี beta error มากขึ้นเรื่อย ๆ ภาพล่าง ๆ คุณภาพของรูปห่วยมาก เราเพียงแต่คำนวณหา p-value ออกมาได้เป็นตุเป็นตะ ทั้งที่มีไม่กี่ pixel
กรณีหลัง ค่า p-value ไม่ใช่ว่าได้มาจากกองข้อมูลดิบโดยตรง แต่ได้มาจากการคาดการณ์ขยายความ จากข้อมูลดิบที่มีอยู่เพียงน้อยนิด
สมมติว่า มีใช้ข้อมูลแค่ไม่กี่ pixel สรุปปรากฎการณ์ดูดาวว่า ดาวดวงนั้น จริง ๆ แล้ว มันเป็นดาวคู่ ด้วย p-value ระดับ 0.000,001 หรือระดับ 1 ในล้าน
กรณีนี้ ก็จะเป็นเรื่องที่เกิดขึ้นได้ แต่ปัญหาคือ power ก็จะต่ำ เพราะผมไปใช้แค่ไม่กี่ pixel มาฟันธง ทั้งที่ปรากฎการณ์แบบ 1 ใน ล้าน ก็ควรมี pixel เยอะ ๆ หน่อย ระดับเป็นล้าน ๆ pixel จึงจะมีพลัง (power) ในการบอกว่า มันซ้อนเหลื่อมแค่ระดับ 1 pixel จากล้าน pixel
ถ้า beta error ต่ำมาก ๆ หมายความว่า pixel จริงมีเยอะมาก จนนับระดับการซ้อนเหลื่อมจากจำนวน pixel กันตรง ๆ ได้
ถ้า beta error สูง หมายความว่า ขาดแคลน pixel จริง จนต้องคำนวณคาดเดาขยายผลว่า มันคงจะซ้อนเหลื่อมกัน
ดังนั้น เวลาดูข้อสรุปสถิติ นอกจากดูค่า alpha, p-value แล้ว ยังต้องดู beta error ด้วย
power มาก ก็เหมือน pixel มาก คุณภาพของข้อมูลที่ประจักษ์กับตาจะสูง ก็จะมีค่า beta error ต่ำ
power น้อย ก็เหมือน pixel น้อย คุณภาพของข้อมูลที่ประจักษ์กับตาจะต่ำ ก็จะมีค่า beta error สูง
แต่ไม่ว่า pixel จะมากหรือน้อย ก็ไม่แปลกที่จะทำให้ได้ p-value เดียวกัน
แต่คุณภาพของข้อมูลที่ประจักษ์กับตา อาจจะต่างกันก็ได้
beta error ก็จะเป็นตัวบอกว่า เรากำลังใช้ข้อมูลนิดเดียว ไปฟันธงปรากฎการณ์หายากอยู่รึเปล่า
beta error ต่ำ คือ ใช้ข้อมูลมากพอ ไปฟันธงปรากฎการณ์ที่หาดูได้ยาก
beta error สูง คือ ใช้ข้อมูลนิดเดียว ไปฟันธงปรากฎการณ์ที่หาดูได้ยาก
หรือกล่าวอีกนัยหนึ่ง ค่า p-value เดียวกัน จะน่าเชื่อถือหรือไม่ ขึ้นกับขนาดของการสุ่มวัด (sample size) เทียบได้กับการที่เราฟังธงโดยใช้จำนวน pixel ที่แตกต่างกัน
pixel มาก =sample size มาก = beta error ต่ำ ไม่จำเป็นต้องทำให้เกิดนัยสำคัญทางสถิติ
ก็เหมือนผมตั้งกล้องให้บันทึก 10 ล้านพิกเซลต่อรูป แต่ภาพยังเบลอได้

10 ล้านพิกเซล คือมี beta error ต่ำ
ภาพเบลอ คือ alpha error สูง
มี pixel เยอะ (beta error ต่ำ) ก็ไม่เกี่ยวกับการหายเบลอ (ไม่ทำให้ p-value น้อยลง)

ภาพวิวสองภาพนี้ มี pixel พอกัน จึงกล่าวได้ว่า มี power หรือ beta error ระดับเดียวกัน
แต่ความคมชัดต่างกัน จึงกล่าวได้ว่า alpha error ผิดกันเยอะ
ภาพที่คม มี alpha error น้อยกว่า
ภาพเบลอ ก็มี alpha error สูงกว่า
ภาพที่ใช้ได้ ควรคมชัด (alpha error ต่ำ) และมี pixel มากพอสมควร (มี power สูงพอ หรือมี beta error ต่ำ)
แต่ถ่ายภาพมาชัด ตั้ง pixel ภาพสูง ๆ ก็ไม่ได้รับประกันว่า ภาพดี
ภาพดี เขาดูเรื่องแสงเงา เรื่ององค์ประกอบภาพ เสริมเข้าไปด้วย
เวลาดูข้อสรุปทางสถิติจากงานวิจัยก็เป็นเช่นกัน คือต้องดูว่า ต่างทางสถิติไหม ต่างทางปฎิบัติไหม และมี power พอไหม
ถ้า power น้อย แสดงว่า ทดลองมาน้อยไปหน่อย ไม่ควรไว้ใจ
พวกอาหารเสริมที่กระหน่ำโฆษณา ว่าเขาวิจัยได้ผลดีสุดยอด ไปดูให้ดี ๆ เถอะ ค่า power มักมีปัญหา คือมักทดลองในกลุ่มเล็ก ๆ หากได้ข้อสรุปที่คมชัดทางสถิติ (แต่ power อ่อนปวกเปียก) ก็จะโม้ในลักษณะที่บอกว่า "แตกต่างอย่างชัดเจนทางสถิติ เมื่อเทียบกับการดื่มน้ำเปล่า" โดยไม่กล้าแตะประเด็นว่า "จำนวนคนที่เข้าไปเป็นตัวอย่างทดลองมีไม่กี่คน"
สนใจอ่าน เรียนสถิติด้วยภาพ แบบครบทุกตอน เข้าไปที่
http://www.gotoknow.org/posts?tag=เรียนสถิติด้วยภาพ
ความเห็น (10)
ขอบคุณคะ
อ.คะถ้าจะจำว่า P-value เหมือนการจับมือกัน 2ข้าง ถ้าP-value มากแสดงว่าเราจับมือแน่น นิ้วเกยกันมาก
แต่ถ้า P-value น้อย แสดงว่าจับห่างๆ หลวมๆ นิ้วเกยกันน้อย จะได้รึเปล่าคะ

- ก่อนอื่นต้องเข้าใจว่า แม้แต่นิยามที่ให้ไว้ตรงนี้ ที่ดูระดับการเกยกัน ก็ไม่ใช่นิยามที่ถูกต้อง เป็นเพียงการ "ประมาณ" ปรากฎการณ์ด้วยอุปมาไปแล้วชั้นหนึ่ง ไม่แม่นยำ เป็นเพียงความหมายคร่าว ๆ
- ถ้าเอาอุปมาอีกชั้นหนึ่งมาใช้ "ประมาณ" อุปมาชั้นแรก ความหมายจะห่างออกไปจนถึงจุดที่เข้าใจผิดได้ง่าย จึงควรเลี่ยง ถ้าจะอุปมาจริง ๆ ต้องงอกจากความเข้าใจตรงของประสบการณ์ของตัวเอง
- ขอให้ตั้งต้นจากจุดศูนย์กลางของแต่ละหย่อมข้อมูลก่อน
- แล้วเกิดริ้ววงกลมที่แผ่ออกไปรอบข้าง ริ้วที่ขยายตัวออก มีขนาดหน้ากว้างก็คือ confidence interval และเนื้อส่วนขอบก็คือ alpha level โดยวงกลมทั้งสอง ต้องโตให้ confidence interval งอกเท่ากันตลอดเวลา
- พอวงกลมทั้งสองวงมาแตะตรงไหน ก็หยุดตรงนั้น ก็จะได้ p-value
- ประเด็นคือ ข้อมูลดิบในประเด็นอะไรก็แล้วแต่ จะเป็นข้อมูลดิบมิติเดียว ผมทำให้เป็นภาพสองมิติเพื่อให้เกิดภาพในใจที่สมองเราชินในการตีความ จริง ๆ แล้ว ข้อมูลดิบจะไม่ได้เกิดใน "แผ่นระนาบ" สองมิติอย่างนี้ แต่เกิดบน "เส้น" มิติเดียว ผมใช้สองมิติโดยพลการ จึงเสี่ยงมากที่จะเข้าใจผิดโดยใช้อุปมาอื่นซ้อนไปอีกชั้น
อ.ครับ ค่า beta error นี่ ถ้าในโปรแกรมเช่น SPSS เนี่ย ดูจากจุดไหนครับ
หรือว่าเราสรุปจาก sample ที่มากก็ถือว่าโอใช่มั้ยครับ

-
ฺBeta error นี่ เขามีสูตรคำนวณ
- เพียงแต่ผมเขียนเรื่อง "เรียนสถิติด้วยภาพ" ไม่ได้เขียนเรื่อง "เรียนสถิติด้วยสมการ" ก็เลยไม่สนใจเรื่องสูตรพวกนั้น
- แต่ตำรามีครับ
- SPSS นี่ เอ ไม่รู้สิ ไม่ได้ใช้เลย เคยใช้ล่าสุดสมัย DOS 5.0 (Intel 8088) ซึ่งคิดว่า version นั้น น่าจะเก่าไป "นิดหน่อย"

- ขอบคุณคะ อ.จะอ่านและทำความเข้าใจใหม่คะ
- ถ้ามีคำถามที่ไม่เข้าใจ ขออนุญาตนำมาเรียนถามอีกนะคะ เพื่อนำไปใช้ในอนาคตคะ
ดังนั้น เวลาดูข้อสรุปสถิติ นอกจากดูค่า alpha, p-value แล้ว ยังต้องดู beta error ด้วย
อาจารย์ คะ คือต้องดูขนาดของตัวอย่าง,ข้อมูลดิบ ที่เก็บสุ่มมาด้วย..เข้าใจถูกต้องมั้ยคะ
ประเด็นคือ ข้อมูลดิบในประเด็นอะไรก็แล้วแต่ จะเป็นข้อมูลดิบมิติเดียว ผมทำให้เป็นภาพสองมิติเพื่อให้เกิดภาพในใจที่สมองเราชินในการตีความ จริง ๆ แล้ว ข้อมูลดิบจะไม่ได้เกิดใน "แผ่นระนาบ" สองมิติอย่างนี้ แต่เกิดบน "เส้น" มิติเดียว ผมใช้สองมิติโดยพลการ จึงเสี่ยงมากที่จะเข้าใจผิดโดยใช้อุปมาอื่นซ้อนไปอีกชั้น
ไม่เข้าใจตรงนี้ ข้อมูลดิบทำไมต้องเป็นมิติเดียว
เกิดเป็นการศึกษาที่มี multifactor ล่ะคะอาจารย์
(ถามแบบไม่รู้อีกแล้ว)
สวัสดีครับ คุณหมอ  ภูสุภา
ภูสุภา
- ใช่แล้วครับ beta error เป็นผลจาก sampling size หรือพูดอีกนัยหนึ่ง sampling size ก็เป็นตัวบอกเป็นนัย ๆ ว่า ข้อสรุปของเรา มีรายละเอียดหนุนหลังมากพอหรือเปล่า
- งานวิจัยทางการแพทย์จะนิยมระบุไว้ด้วยว่า beta เท่าไหร่ (แต่บอกเป็น power แทน เช่น สเกลเล็กหน่อย ก็อาจบอกว่า งานวิจัยนี้มี power 80 %)
- ข้อมูลดิบในโลกจริงมีหลายมิติ แต่ละมิติแยกขาดออกไปจากกัน แต่เวลาเราพูดถึงข้อมูลเดี่ยว ๆ ตัวใดตัวหนึ่ง ก็เหมือนเราดูข้อมูลมิติเดียว จะเห็นเป็นจุดต่าง ๆ อยู่บนเส้น ซึ่งสมองของเราตีความไม่ค่อยถูก ผมจึงใช้ภาพสองมิติแทน เพื่อบรรยายข้อมูล มิติที่สองที่งอกมา เป็นรายการแปลกปลอมครับ หรืออย่างเช่นภาพเงาะ กลายเป็นภาพ 3 มิติไป นั่นก็มีแถมมิติแปลกปลอมมาให้
- พูดง่าย ๆ คือ ที่ว่ามาทั้งหมด ยังเป็น univariate ไม่ได้เป็น multivariate ครับ แต่ที่เห็นหลายมิติ เพราะผมใส่แถมไปให้มองเห็นเป็นภาพวัตถุที่เราคุ้นชินในชีวิตประจำวัน มิติแปลกปลอมที่แถม ไม่ได้มีความหมายอะไรทั้งสิ้น เป็นการบังคับให้เส้นใน 1 มิติหมุนรอบตัวเองเกิดภาพวงกลมในสองมิติธรรมดา
ขอบคุณอาจารย์มากนะคะเรียนสถิติมาเพิ่งถึงบางอ้อก้อเพราะอ่านผลงานของอาจารย์เลยค่ะ
ผลิตผลงานดีๆอย่างนี้ออกมาเรื่อยๆนะคะ รอติดตามผลงานอาจารย์อยู่นะคะ ^_^